Probit Modeling
I should have put more prior modeling in my Bayesian R book. One of the obvious advantages of the Bayesian approach is the ability to incorporate prior information. I’ll illustrate the use of informative priors in a simple setting — binary regression modeling with a probit link where one has prior information about the regression vector.
At my school, many students typically take a precalculus class that prepares them to take a business calculus class. We want our students to do well (that is, get a A or B) in the calculus class and wish to understand how the student’s performance in the precalculus class and his/her ACT math score are useful in predicting the student’s success.
Here is the probit model. If y=1 and y=0 represent respectively a student doing well and not well in the calculus class, then we model the probability that y=1 by
Prob(y=1) = Phi(beta0 + beta1 (PrecalculusGrade) + beta2 (ACT))
where Phi() is the standard normal cdf, PrecalculusGrade is 1 (0) if the student gets an A (B or C) in the precalculus class, and ACT is the math ACT score.
Suppose that the regression vector beta = (beta0, beta1, beta2) is assigned a multivariate normal prior with mean vector beta0 and precision matrix P. Then there is a simple Gibbs sampling algorithm for simulating from the posterior distribution of beta. The algorithm is based on the idea of augmenting the problem with latent continuous data from a normal distribution.
Although you might not understand the code, one can implement one iteration of Gibbs sampling by three lines of R code:
z=rtruncated(N,LO,HI,pnorm,qnorm,X%*%beta,1)
mn=solve(BI+t(X)%*%X,BIbeta0+t(X)%*%z)
beta = t(aa) %*% array(rnorm(p), c(p, 1)) + mn
Anyway, I want to focus on using this model with prior information.
1. First suppose I have a “prior dataset” of 50 students. I fit this probit model with a vague prior on beta. The inputs to the function bayes.probit.prior are (1) the vector of binary responses y, (2) the covariate matrix X, and (3) the number of iterations of the Gibbs sampoler.
fit1=bayes.probit.prior(prior.data[,1],prior.data[,-1],1000)
2. I compute the posterior mean and posterior variance-covariance matrix of the simulated draws of beta. I use these values for my multivariate normal prior on beta.
prior=list(beta=apply(fit1,2,mean),P=solve(var(fit1)))
(Note that I’m inputting the precision matrix P that is the inverse of the var-cov matrix.)
3. Using this informative prior, I fit the probit model with a new sample of 100 students.
fit2=bayes.probit.prior(DATA[,1],DATA[,-1],10000,prior=prior)
The only change in the input is that I input a list “prior” that includes the mean “beta” and the precision matrix P.
4. Now I summarize my fit to learn about the relationship of previous grade and ACT on the success of the calculus students. I define a grid of ACT scores and consider two sets of covariates corresponding to students who were not successful (0) and successful (1) in precalculs.
act=seq(15,29)
x0=cbind(1,0,act)
x1=cbind(1,1,act)
Then I use the function bprobit.probs to obtain posterior samples of the probability of success in calculus for each set of covariates.
fit.x0=bprobit.probs(x0,fit2)
fit.x1=bprobit.probs(x1,fit2)
I graph the posterior means of the fitted probabilities in the below graph. There are two lines — one corresponding to the students who aced the precalculus class, and another line corresponding to the students who did not ace precalculus.
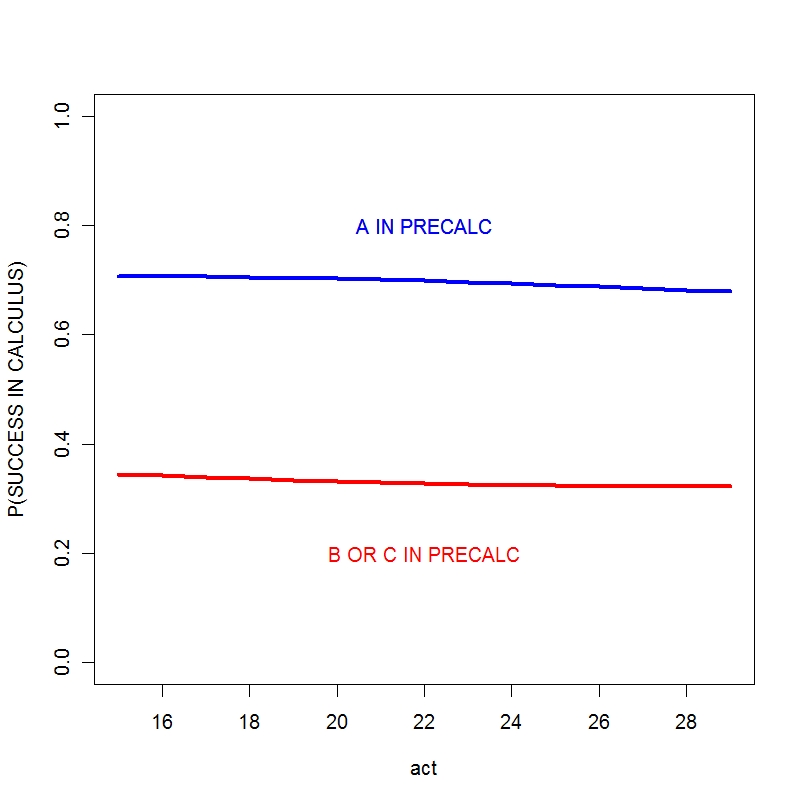 Several things are clear from this graph. The performance in the precalc class matters — students who ace precalculus have a 30% higher chance of succeeding in the calculus class. On the other hand, the ACT score (that the student took during high school) has essentially no predictive ability. It is interesting that the slopes of the lines are negative, but these clearly isn’t significant.
Several things are clear from this graph. The performance in the precalc class matters — students who ace precalculus have a 30% higher chance of succeeding in the calculus class. On the other hand, the ACT score (that the student took during high school) has essentially no predictive ability. It is interesting that the slopes of the lines are negative, but these clearly isn’t significant.
